Neue KI-Modelle

OpenAI veröffentlicht ChatGPT Images 2.0 - Test mit Waschbär und Funkgerät
OpenAI hat ChatGPT Images 2.0 veröffentlicht, ihr neues Bildgenerierungsmodell. Simon Willison testete das neue Modell gegen die Vorgängerversion und Googles Nano Banana mit einem 'Wo ist Waldo'-Style Prompt nach einem Waschbären mit Funkgerät. Die Ergebnisse zeigen deutliche Unterschiede in der Bildqualität und Promptverständnis.
Mehr lesen →
ChatGPT Images 2.0 zeigt überraschend gute Text-in-Bild-Generierung
OpenAI hat mit ChatGPT Images 2.0 ein neues Bildgenerierungsmodell veröffentlicht, das deutliche Verbesserungen bei der AI-Fähigkeiten zeigt. Das Modell zeichnet sich besonders durch seine überraschend gute Fähigkeit aus, Text in generierten Bildern darzustellen.
Mehr lesen →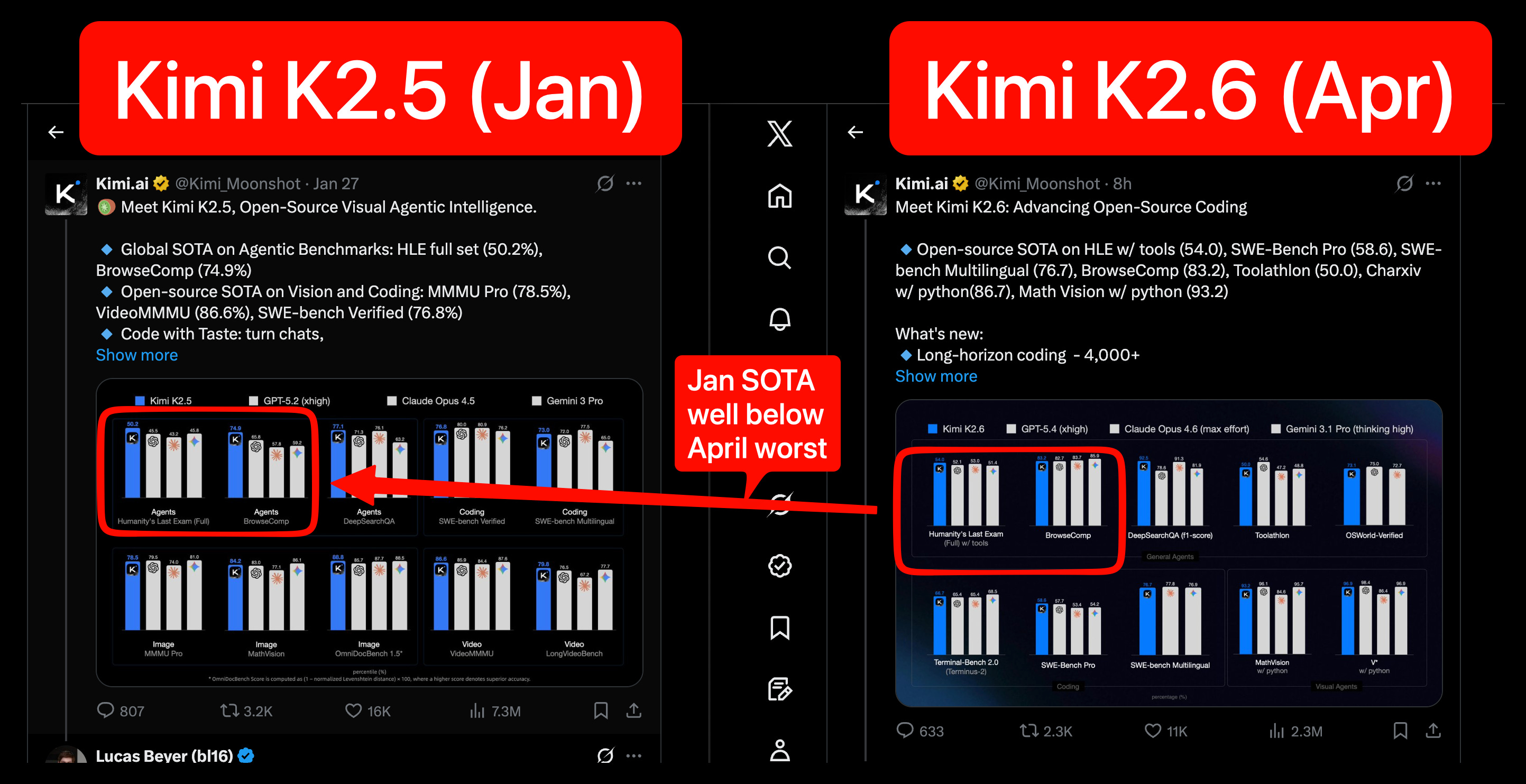
Moonshot Kimi K2.6: Weltführendes Open-Source-Modell erhält Update
Moonshot hat sein Kimi-Modell auf Version K2.6 aktualisiert, das laut Ankündigung mit Claude Opus 4.6 konkurrieren kann. Das Update positioniert Kimi weiterhin als führendes Open-Source-Sprachmodell vor dem erwarteten DeepSeek v4 Release.
Mehr lesen →
Anthropic stellt Claude Mythos Preview vor - Cybersecurity-Modell soll Beziehungen zur US-Regierung verbessern
Anthropic hat ein neues Cybersecurity-fokussiertes KI-Modell namens Claude Mythos Preview vorgestellt. Das Modell könnte dazu beitragen, die angespannten Beziehungen zwischen dem Unternehmen und der Trump-Administration zu entspannen, die Anthropic zuvor als 'radikal links' kritisiert hatte.
Mehr lesen →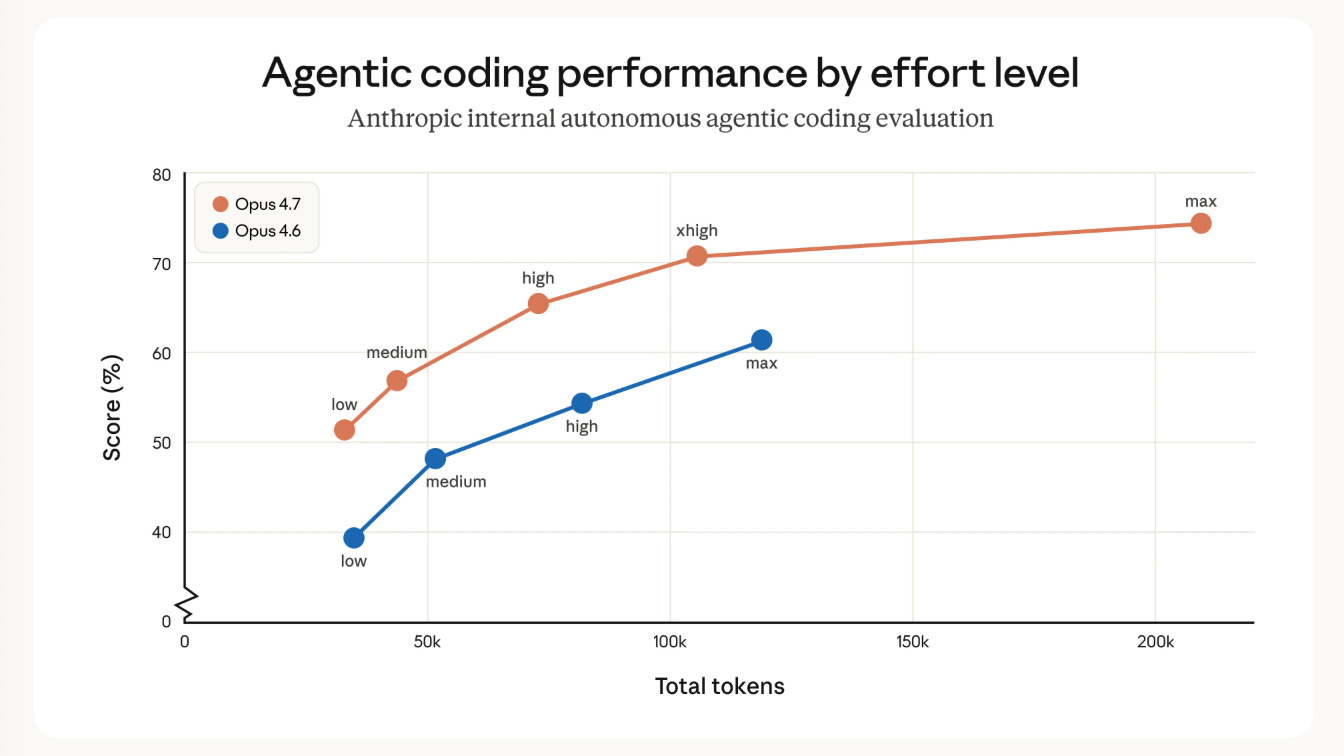
Anthropic veröffentlicht Claude Opus 4.7 - Verbesserungen in allen Bereichen
Anthropic hat Claude Opus 4.7 veröffentlicht, das laut Ankündigung in jeder Dimension eine Stufe besser als Version 4.6 sein soll. Das neue Modell beansprucht den Status des neuen State-of-the-Art-Modells.
Mehr lesen →
Physical Intelligence stellt π0.7 vor - neues KI-Modell für Roboter-Allzwecksteuerung
Das Robotik-Startup Physical Intelligence hat sein neues Modell π0.7 vorgestellt, das als früher Schritt zu einem universellen Roboter-Gehirn konzipiert ist. Das Modell kann laut Unternehmen Aufgaben bewältigen, für die es nicht explizit trainiert wurde.
Mehr lesen →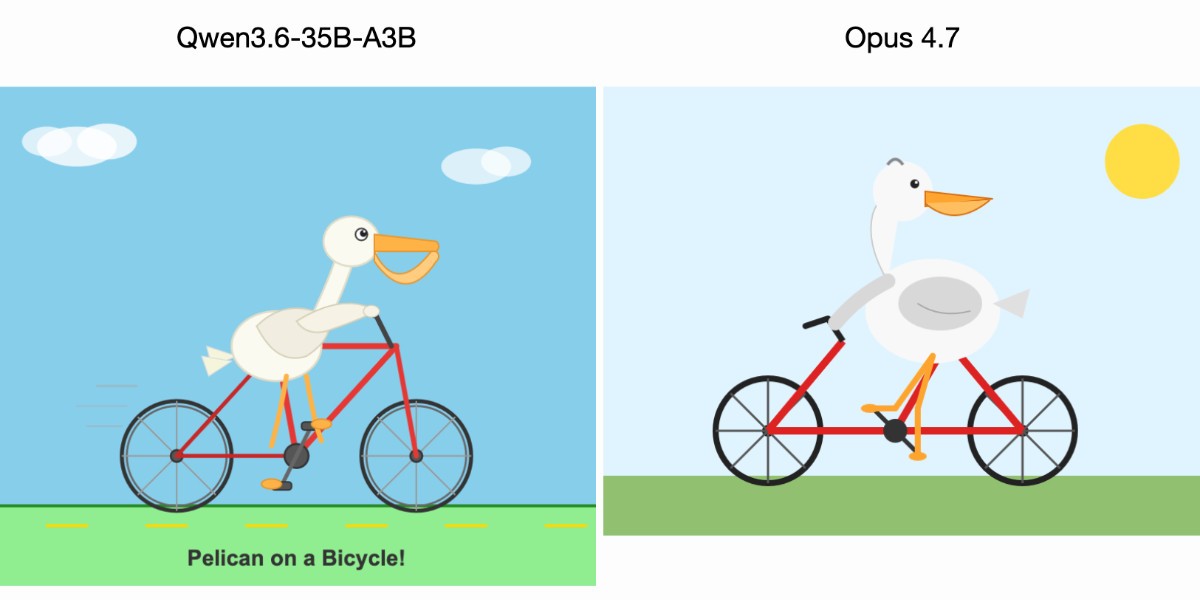
Qwen3.6-35B-A3B generiert bessere SVGs als Claude Opus 4.7 in Pelikan-Benchmark
Simon Willison vergleicht die neuen Modelle Qwen3.6-35B-A3B von Alibaba und Claude Opus 4.7 von Anthropic anhand seines informellen "Pelikan auf Fahrrad"-Benchmarks. Das lokal auf seinem MacBook laufende Qwen-Modell erzeugte dabei überraschenderweise bessere SVG-Grafiken als Anthropics neues Flaggschiff-Modell.
Mehr lesen →
Anthropic veröffentlicht Claude Opus 4.7 als neues Flaggschiff-Modell
Anthropic hat Claude Opus 4.7 als bisher stärkstes allgemein verfügbares Modell veröffentlicht. Das Update bringt Verbesserungen bei komplexen Software-Engineering-Aufgaben, Bildanalyse und Instruktionsbefolgung mit sich.
Mehr lesen →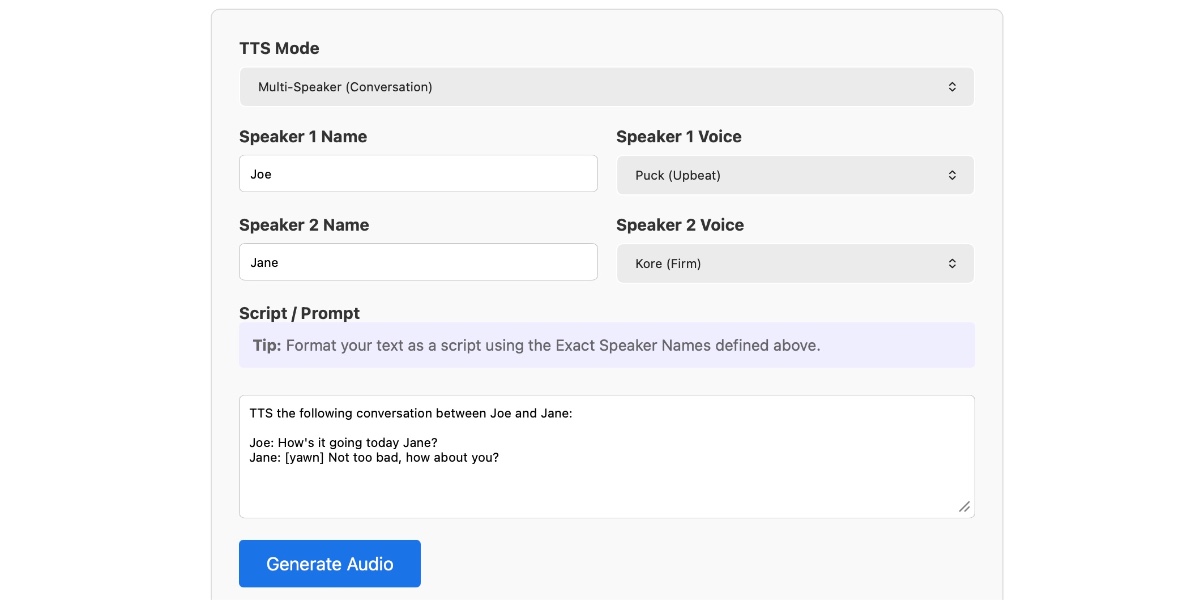
Google veröffentlicht Gemini 3.1 Flash TTS - Text-zu-Sprache mit Prompt-Steuerung
Google hat Gemini 3.1 Flash TTS veröffentlicht, ein neues Text-zu-Sprache-Modell, das über detaillierte Prompts gesteuert werden kann. Das Modell ist über die Gemini API verfügbar und ermöglicht die Generierung von Audio mit verschiedenen Stimmen, Akzenten und Sprechstilen.
Mehr lesen →OpenAI stellt GPT-5.4-Cyber vor - Cybersicherheits-Variante als Antwort auf Claude Mythos
OpenAI hat GPT-5.4-Cyber angekündigt, eine speziell für defensive Cybersicherheit trainierte Modellvariante. Das Modell ist Teil des erweiterten 'Trusted Access for Cyber'-Programms, bei dem Nutzer sich über Ausweisverifikation für reduzierten Zugang zu Sicherheitstools qualifizieren können.
Mehr lesen →Cohere veröffentlicht Open-Source-Sprachmodell für Transkription
Cohere hat ein neues Open-Source-Sprachmodell mit 2 Milliarden Parametern speziell für die Transkription von Sprache entwickelt. Das Modell ist für Consumer-GPUs optimiert und unterstützt 14 Sprachen, wodurch es für Self-Hosting-Szenarien geeignet ist.
Mehr lesen →
Mistral veröffentlicht Open-Source-Modell für Sprachgenerierung
Mistral hat ein neues Open-Source-Modell für Sprachgenerierung vorgestellt. Das Modell ist so kompakt und effizient, dass es auch auf Smartphones und Smartwatches ausgeführt werden kann.
Mehr lesen →
Google DeepMind stellt Gemma 3 270M vor: Kompaktes KI-Modell für höchste Effizienz
Google DeepMind hat Gemma 3 270M vorgestellt, ein neues kompaktes KI-Modell mit 270 Millionen Parametern, das für besonders effiziente Anwendungen entwickelt wurde. Das Modell soll trotz seiner geringen Größe leistungsstarke KI-Funktionen bieten.
Mehr lesen →
DeepMind stellt AlphaEarth Foundations vor - KI für detaillierte Planetenkartierung
DeepMind hat AlphaEarth Foundations angekündigt, ein KI-System zur Kartierung der Erde in bisher unerreichter Detailgenauigkeit. Das System verspricht neue Möglichkeiten für Umweltüberwachung und Klimaforschung durch präzise Erdbeobachtung.
Mehr lesen →
AlphaGenomeDecode: DeepMinds KI-System zur Krankheitsvorhersage durch Genomanalyse
DeepMind hat mit AlphaGenomeDecode ein neues KI-System vorgestellt, das genetische Daten analysiert, um Krankheiten präzise zu identifizieren. Das System nutzt fortschrittliche Machine Learning-Algorithmen zur Dekodierung komplexer genomischer Muster.
Mehr lesen →
Meta stellt Canopy Height Maps v2 vor: Präzise KI-basierte Waldkartierung
Meta hat in Zusammenarbeit mit dem World Resources Institute Canopy Height Maps v2 (CHMv2) veröffentlicht, ein Open-Source-Modell für die weltweite Waldkartierung. Das auf DINOv3 basierende System verbessert die Genauigkeit der Baumhöhenmessung erheblich und erreicht einen R²-Wert von 0,86 gegenüber 0,53 der Vorgängerversion.
Mehr lesen →
Meta stellt SAM Audio vor: Erstes multimodales KI-Modell für Audio-Separation
Meta hat SAM Audio vorgestellt, ein bahnbrechendes KI-Modell, das jede Art von Sound aus komplexen Audio-Mischungen isolieren kann - durch Text, visuelle Hinweise oder Zeitmarkierungen. Das Modell basiert auf dem Perception Encoder Audiovisual (PE-AV) und erreicht State-of-the-Art-Leistung bei verschiedenen Audio-Separationsaufgaben. Zusätzlich wurden SAM Audio-Bench und SAM Audio Judge als erste Benchmarks und Bewertungsmodelle für Audio-Separation veröffentlicht.
Mehr lesen →
Meta stellt SAM 3D vor: KI-Modelle für 3D-Rekonstruktion aus einzelnen Bildern
Meta hat SAM 3D vorgestellt, eine neue Familie von KI-Modellen, die aus einzelnen 2D-Bildern detaillierte 3D-Rekonstruktionen von Objekten und menschlichen Körpern erstellen können. Die Modelle SAM 3D Objects und SAM 3D Body setzen neue Standards für die 3D-Rekonstruktion in realen Szenarien und werden bereits in Facebook Marketplace's neuer "View in Room"-Funktion eingesetzt.
Mehr lesen →
Meta veröffentlicht SAM 3: KI-Modell für präzise Objekt-Segmentierung in Bildern und Videos
Meta stellt das Segment Anything Model 3 (SAM 3) vor, ein einheitliches KI-Modell für Objekterkennung, -segmentierung und -verfolgung in Bildern und Videos mittels Text-, Beispiel- und visueller Eingaben. Zusätzlich wird der Segment Anything Playground als experimentelle Plattform und SAM 3D für 3D-Rekonstruktion aus einzelnen Bildern veröffentlicht.
Mehr lesen →
Meta stellt Omnilingual ASR vor: Spracherkennung für über 1.600 Sprachen
Meta hat Omnilingual ASR veröffentlicht, ein bahnbrechendes System für automatische Spracherkennung, das über 1.600 Sprachen unterstützt, darunter 500 unterrepräsentierte Sprachen. Das System basiert auf einem 7-Milliarden-Parameter wav2vec 2.0 Modell und erreicht state-of-the-art Performance mit Zeichenfehlerraten unter 10% für 78% der unterstützten Sprachen.
Mehr lesen →KI-News direkt ins Postfach
Jeden Morgen um 8:30 Uhr — die wichtigsten KI-Nachrichten zusammengefasst.